 Meducationline365
Meducationline365
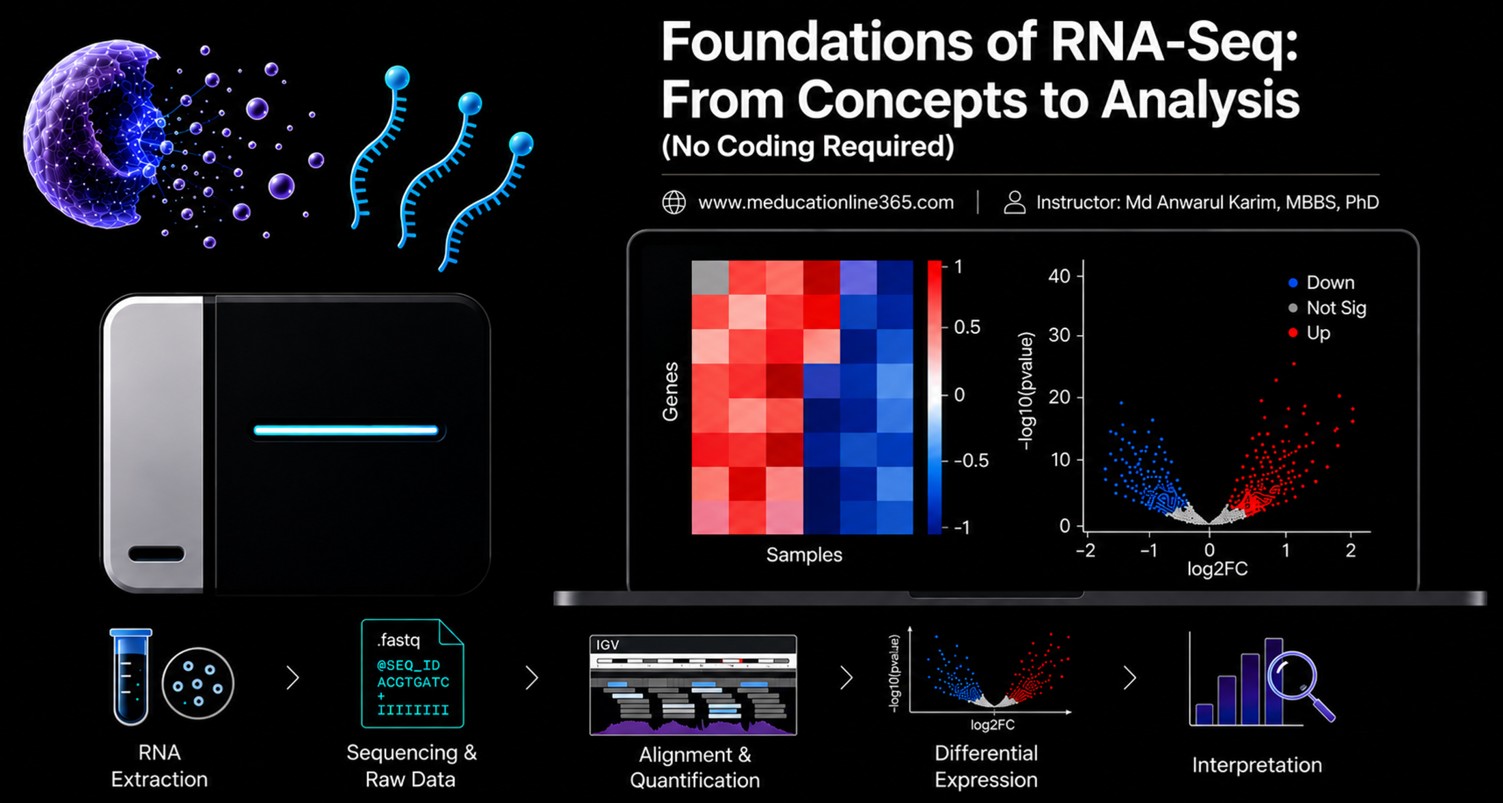
Foundations of RNA-Seq: From Concepts to Analysis — No Coding Required
Course Summary
Learn the complete workflow of RNA-Seq — from essential biological principles and next-generation sequencing (NGS) concepts to practical data analysis. This no-coding course is designed for medical and biomedical learners who want to confidently perform RNA-Seq data analysis.
Course Description
This course introduces you to the world of NGS and transcriptomics in a clear, step-by-step manner. The focus is on building a broad conceptual understanding and hands-on analysis skills that empower you to perform RNA-Seq data analysis independently, without getting lost in complex statistics, technologies, or coding.
The course begins with the fundamental principles of gene expression and NGS, provides an overview of the RNA-Seq workflow, and then guides you through the complete RNA-Seq analysis pipeline using a user-friendly analysis environment that requires no coding skills.
Through detailed instructions with recorded practical videos in Bangla, live interactive sessions, curated external resources, readings, worksheets, and quizzes, you will learn to perform key steps in RNA-Seq data analysis, including quality control, read alignment, gene expression quantification, differential expression, and enrichment analysis. A real published dataset from an international peer-reviewed journal will be used throughout the course, allowing you to practice each step of the workflow in a structured, hands-on manner, and eventually reproduce the results of the published paper. In the final phase, you will complete a capstone project, presenting your findings in a format that simulates a research presentation, thus building your confidence and competence to independently perform RNA-Seq analyses.
By the end of the course, you will be able to:
- Explain key concepts and terminology in NGS and RNA-Seq.
- Perform RNA-Seq data analysis from raw reads to biological interpretation without any coding.
- Present your RNA-Seq analysis results in a format that mimics a research presentation.
This course is ideal for:
Undergraduate students, graduate students, postdocs, and professionals in medicine, biology, or related fields who have no prior coding or bioinformatics experience. It is particularly helpful for those who want to conduct research using RNA-Seq or prepare themselves for higher studies in competitive research programs.
Instructor:
This course will be taught by Dr. Md Anwarul Karim (Mijan), currently a Postdoctoral Researcher at Baylor College of Medicine, USA. Dr. Karim is a medical graduate from Chittagong Medical College and holds a PhD in Genetics from the University of Hong Kong.
RNA-Seq Interest Form
Click below to express your interest for the course and get connected.
➜ Fill Out RNA-Seq Interest FormFoundations of RNA-Seq: From Concepts to Analysis
No Coding RequiredA complete RNA-Seq learning experience combining theory and hands-on analysis using real sequencing data. Below is an overview of the hands-on skills covered in the practical section.


























Course Timeline
Foundations of RNA-Seq: From Concepts to Analysis (No Coding Required)
Md Anwarul Karim, MBBS, PhD
Course Format
- Hands-on practical videos (Bangla): Clear step-by-step demonstrations and explanation of key topics/steps. This is the most high-value resource of this course.
- Curated conceptual videos (English): This is to further enhance understanding of the practical contents.
- Interactive live sessions: To interactively discuss the key concepts and Q/A.
- Concept notes and MCQ questions: Concise concept notes, problem-based and simple recall type MCQs to summarize key topics and self-assessment.
- WhatsApp community support: For troubleshooting, peer learning, and faster announcements.
- Delivered via Moodle: A learning management system widely used by top global universities.
- Mostly flipped classroom model: The core learning content is delivered through Moodle for structured self-paced learning, while live interactive sessions are dedicated to discussing key concepts, addressing questions, and reinforcing understanding.
Estimated course workload
| Component | Approximate duration |
|---|---|
| Hands-on practical videos | ~6.5 hours |
| Curated conceptual videos | ~7 hours |
| Live sessions | Variable |
| Notes / MCQs / Capstone | Variable |
Recommended commitment: 5–10 hours per week
Note: The durations shown represent the total length of the video content. The actual time required for understanding, note-taking, and independently performing the practical exercises may vary significantly depending on individual background and learning pace.